
The BOUNCE automated data cleaning process aims at detecting and correcting (or removing) any “messy”, “noisy”, corrupted or erroneous data entries of a dataset. To achieve this, it provides the configurable mechanism that increases the data quality of a dataset, which is usually composed of information originating from a variety of heterogeneous data sources, by increasing the cleanliness and completeness of the dataset to the highest possible degree. In a nutshell, the mechanism executes a multi-step process during which the various incomplete, incorrect or corrupted data entries of a dataset are identified and corrected, transformed or discarded from the dataset. The incoming prospective data are fed to the automated cleaning process of BOUNCE in order to be “cleaned” and stored in BOUNCE Data Lake in an automated and robust manner.
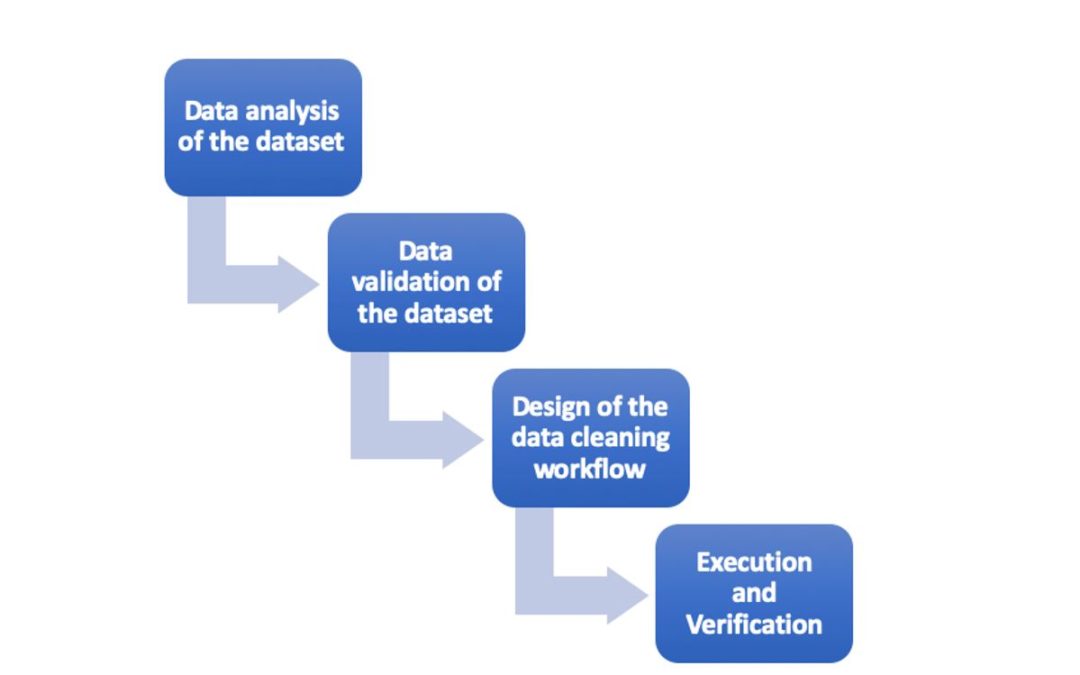
The BOUNCE automated data cleaning process is composed of a set of sequential steps which include:
- Data analysis of the dataset: In this step, the data of the dataset are analysed and the different data fields of the datasets are identified along with the corresponding data aspects such as the type of data, the acceptable format of the data entries, the list of acceptable (in terms of either range or distinct) values, as well as any limitations or restrictions.
- Data validation of the dataset: In this step, the validation (conformance) rules of the data entries are defined. The rules aim to detect the inconsistencies, erroneous entries and any missing data entries in the dataset. The identified conformance errors are later fed to the data cleaning and missing value handling mechanism in order to be addressed or eliminated.
- Design of the data cleaning workflow: In this step, the data cleaning and missing value handling rules are defined. The specific rules will either correct or remove the erroneous data entries or automatically fill-in the missing values in the identified problematic data entries of the dataset in order to eliminate the conformance errors identified by the validation rules. Both the data cleaning and missing value handling rules are connected to a validation rule whose execution results will trigger the execution of the corrective actions on the non-conforming data entries.
- Execution and Verification: In this step, the designed data cleansing workflow incorporating the validation rules, as well as the corresponding the data cleaning and missing value handling rules is executed. As a result, the “cleaned” dataset is produced and all the performed corrective actions are validated with the inspection of the detailed records of the execution.

The BOUNCE automated data cleaning process is provided by the BOUNCE Data Cleaner component which is a core component of the integrated BOUNCE platform. The BOUNCE Data Cleaner is composed of a set of backend processes which are leveraged by the BOUNCE stakeholders through the novel user interface that the BOUNCE Data Cleaner offers. In particular, the validation is rules are defined and executed through the Validator and the list of available rules includes conformance to a specific data type, a pre-defined value range, a list of pre-defined values, value representation, regular expression patterns, value uniformity, uniqueness, non-empty value, cross-field validity and cross-field dependency.

The cleaning rules are defined and executed through the Cleaner which executes the appropriate cleaning actions in order to correct or eliminate the non-conforming data entries from the datasets as identified by the Validator. The list of corrective actions includes the rejection of an inconsistent value and the removal of the specific value from the data fields of the dataset or the removal of the complete record or line from the dataset and the replacement of an inconsistent value with a statistical value or a predefined value.

Finally, the recording of all the corrective actions which are performed during the execution of the data cleaning workflow is undertaken by the Recorder. The detailed records contain all the information related to the identified error and the corrective action that was performed. Within the context of BOUNCE, 2853 rules in total were applied on the provided datasets.
