
Towards designing a platform that will guarantee uninterrupted data flow and smooth interaction amongst its technical components, the BOUNCE consortium partners led by Singular Logic designed and documented the BOUNCE Platform Reference Architecture. The BOUNCE architecture is a modular architecture that ensures the required flexibility and interoperability of systems, tools and services that are made available to the users of the environment, with the ultimate goal of facilitating secure, transparent, and unobtrusive sharing of data and functionality. This modular architecture safeguards the smooth and effective integration of the several software modules that are developed exploiting multiple technologies and tools from different partners and organisations of the consortium. The following figure illustrates the BOUNCE platform’s architecture and the following paragraphs provide a brief overview of each component of the architecture.
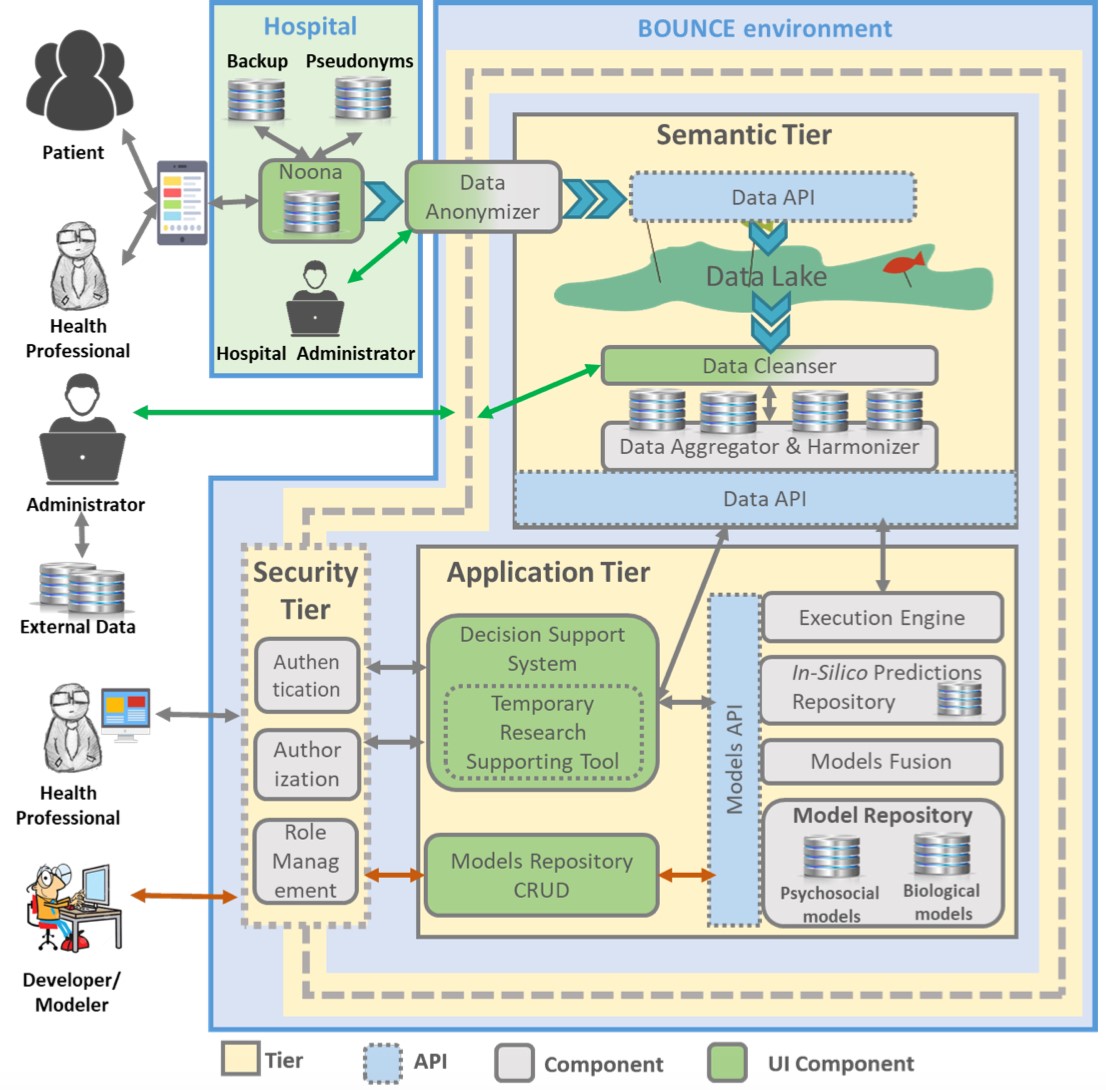
The Access Controller is the component responsible for controlling the access to the different resources of the platform, like the platform’s datasets, added value services and internal components offered through the platform. It manages and processes the requests for granting access to the aforementioned resources with an authentication and authorization mechanism that is based on the Role Based Access Control paradigm.
The Data Lake constitutes the storage repository of the BOUNCE Integrated Platform where anonymized retrospective and prospective data from HUS, IEO, HUJ and CHAMP, along with open data imported from external registries reside.
The Data Anonymiser undertakes the responsibility of anonymizing the data collected before they are pushed into the Data Lake by employing a set of data anonymization techniques that ensure that any kind of private, sensitive or personal information will not be disclosed.
The Data Aggregator is the component responsible for providing access to the available, semantically uplifted data that reside on the Data Lake of the BOUNCE Integrated Platform. Under the hood, the Data Aggregator receives the BOUNCE ontology, the available data sources and the corresponding mappings of the data sources schemas in order to provide the appropriate SPARQL endpoint that enables the query of the integrate data.
The Data Cleaner is implementing the data cleaning functionalities of the BOUNCE Integrated Platform. It performs all actions necessary to safeguard the storage and delivery of consistent, complete and accurate datasets in the Data Lake. It provides the data cleaning processes that detect and correct (or remove) inaccurate or corrupted datasets containing incomplete, incorrect, inaccurate or irrelevant data elements with the purpose of replacing, modifying or deleting these data elements.
The Temporary Research Supporting Tool enables the data exploration and visualization of data and scales. It facilitates the retrieval and visualization of anonymized patient data, as well as data regarding individual scores on each scale and the combination of scores in different biomedical and psychosocial variables.
The BOUNCE Model Repository is responsible for the effective and efficient storage and maintenance of the overall prediction models and the resilience trajectory prediction models of the BOUNCE platform. Within this repository, the relevant model, as well as their parameters, properties and the respective files, are stored and retrieved.
The BOUNCE In Silico Prediction Repository is responsible for persistently storing the predictions of the models developed. Upon the completion of a simulation scenario, the input data and the model utilised within the simulation and the output of the executed simulation are persistently stored and are available for evaluation, comparison and validation.
The Execution Engine is responsible for the execution of a specific model over a selected set of data. The Execution Engine interacts with Data Aggregator to retrieve the required input data, with the Model Repository to retrieve the corresponding model and the In Silico prediction repository to store the produced results of an execution.
The Decision Support System enables the generation of (a) an overall “resilience predictor” score, and (b) scores for specific psychological variables that are important for resilience and adaptation to cancer. It retrieves data about the individual scores on each scale and the combination of scores in different biomedical and psychosocial variables (coming from the current and/or possible previous assessments) in order to produce the required scores.